Google Gemma 4 效能實測報告:跑分大幅拋離上代,31B 與 26B MoE 規格詳解
Google 最新推出嘅 Gemma 4 開源 AI 模型系列,官方基準測試(Benchmark)成績正式曝光。數據顯示,Gemma 4 喺邏輯推理、編程及多模態處理上,效能大幅拋離上一代 Gemma 3 模型。新系列提供 E2B、E4B、26B MoE 及 31B 四款尺寸,全面涵蓋邊緣運算到高階工作站。本文將詳細為大家整合各型號嘅硬件規格與跑分表現,拆解呢款新世代模型嘅實際應用潛力。

Google 釋出 Gemma 4 開源 AI 模型系列:四款尺寸全面規格解析與官方基準測試(Benchmark)成績大公開
人工智能技術嘅競爭越演越烈,模型效能與開源生態成為各大科技巨頭嘅角力場。Google 近日正式宣佈推出全新一代 DeepMind 開放模型系列——Gemma 4,並同步公開咗詳細嘅官方基準測試(Benchmark)成績與模型具體規格。Gemma 4 採用 Apache 2.0 開源許可證授權,提供極大嘅開發自由度。最令業界關注嘅係,根據最新公佈嘅測試數據,Gemma 4 喺各項專業評估中均展現出飛躍性嘅進步,特別喺編程能力與長文本處理上,甚至拋離上一代體積相若嘅模型。本文「5新聞」將為讀者詳細剖析 Gemma 4 嘅四款模型規格,並深入解讀各項跑分數據背後嘅實際意義。
官方硬件規格大解構:由邊緣裝置到高效能伺服器
為咗滿足不同層面嘅運算需求,Google 今次將 Gemma 4 細分為四個版本。根據官方釋出嘅規格資料,我哋可以將佢哋分為「密集模型(Dense Models)」以及「混合專家模型(Mixture-of-Experts, MoE)」兩大類。
1. 密集模型(Dense Models)規格詳情
密集模型採用傳統嘅神經網絡架構,適合需要穩定且全面運算能力嘅場景。Gemma 4 提供咗三款 Dense 模型:
| 規格項目 (Property) | E2B (Effective 2B) | E4B (Effective 4B) | 31B Dense |
|---|---|---|---|
| 總參數量 (Total Parameters) | 2.3B 實際運作 (連嵌入層 5.1B) | 4.5B 實際運作 (連嵌入層 8B) | 30.7B |
| 神經網絡層數 (Layers) | 35 | 42 | 60 |
| 滑動窗口 (Sliding Window) | 512 tokens | 512 tokens | 1024 tokens |
| 上下文長度 (Context Length) | 128K tokens | 128K tokens | 256K tokens |
| 詞彙表大小 (Vocabulary Size) | 262K | 262K | 262K |
| 支援模態 (Supported Modalities) | 文字、圖像、音訊 | 文字、圖像、音訊 | 文字、圖像 |
| 視覺編碼器參數 (Vision Encoder) | 約 150M | 約 150M | 約 550M |
| 音訊編碼器參數 (Audio Encoder) | 約 300M | 約 300M | 不支援音訊 (No Audio) |
從上述資料可以見到,E2B 同 E4B 係專為手機、物聯網等邊緣運算(Edge Computing)裝置設計。雖然佢哋體積細小,但依然具備 128K 嘅上下文處理能力,而且獨家支援原生音訊輸入(內建約 300M 參數嘅音訊編碼器),非常適合用嚟開發離線語音助手。而 31B Dense 則係系列中嘅巨無霸,擁有 256K 超長上下文窗口同高達 550M 參數嘅視覺編碼器,專為企業級複雜圖文分析而設。
2. 混合專家模型(MoE Model)規格詳情
混合專家模型(MoE)嘅特色在於「按需分配」。模型內部包含多個「專家網絡」,每次處理指令時只會啟動部分相關嘅專家,從而喺保持強大效能嘅同時,大幅減低運算資源消耗。
| 規格項目 (Property) | 26B A4B MoE |
|---|---|
| 總參數量 (Total Parameters) | 25.2B |
| 活躍參數 (Active Parameters) | 3.8B |
| 神經網絡層數 (Layers) | 30 |
| 滑動窗口 (Sliding Window) | 1024 tokens |
| 上下文長度 (Context Length) | 256K tokens |
| 詞彙表大小 (Vocabulary Size) | 262K |
| 專家數量 (Expert Count) | 8 個活躍 / 總共 128 個 (外加 1 個共享專家) |
| 支援模態 (Supported Modalities) | 文字、圖像 |
| 視覺編碼器參數 (Vision Encoder) | 約 550M |
呢款 26B A4B MoE 總參數量達到 25.2B,但每次運算時實際啟動(Active)嘅參數只有 3.8B。呢個設計令佢可以喺一般配備高階顯示卡嘅個人電腦或工作站上極速運行,同時擁有媲美大型模型嘅 256K 上下文長度,係尋求「效能與資源平衡」嘅開發者首選。
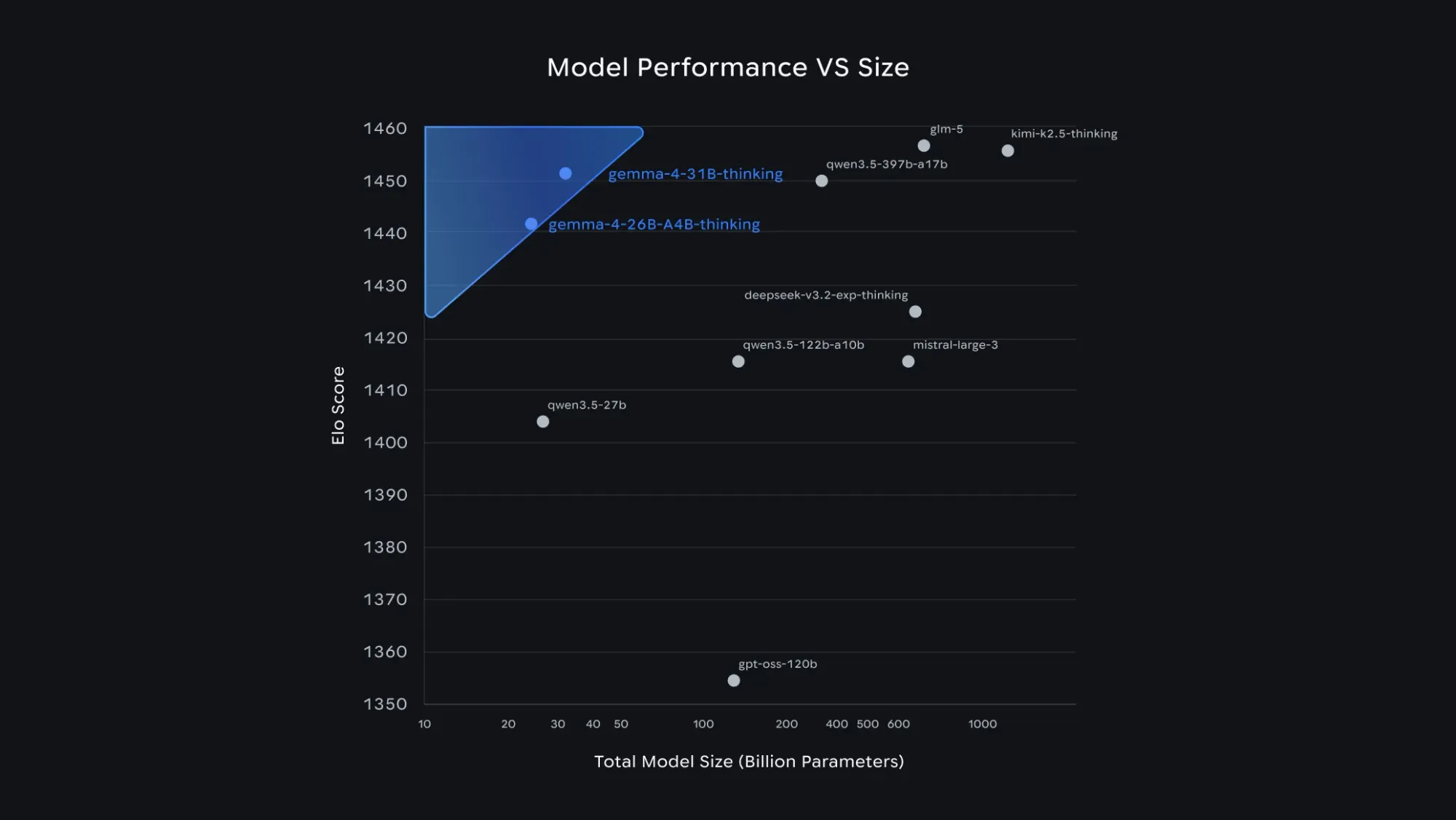
官方基準測試(Benchmark)成績全面公開
為咗客觀評估模型實力,Google 使用咗大量不同嘅數據集進行評估。以下係 Gemma 4 系列與上一代 Gemma 3 27B(非推論版)嘅官方跑分對比。測試涵蓋咗文字生成、編程、視覺以及長文本處理等多個範疇。
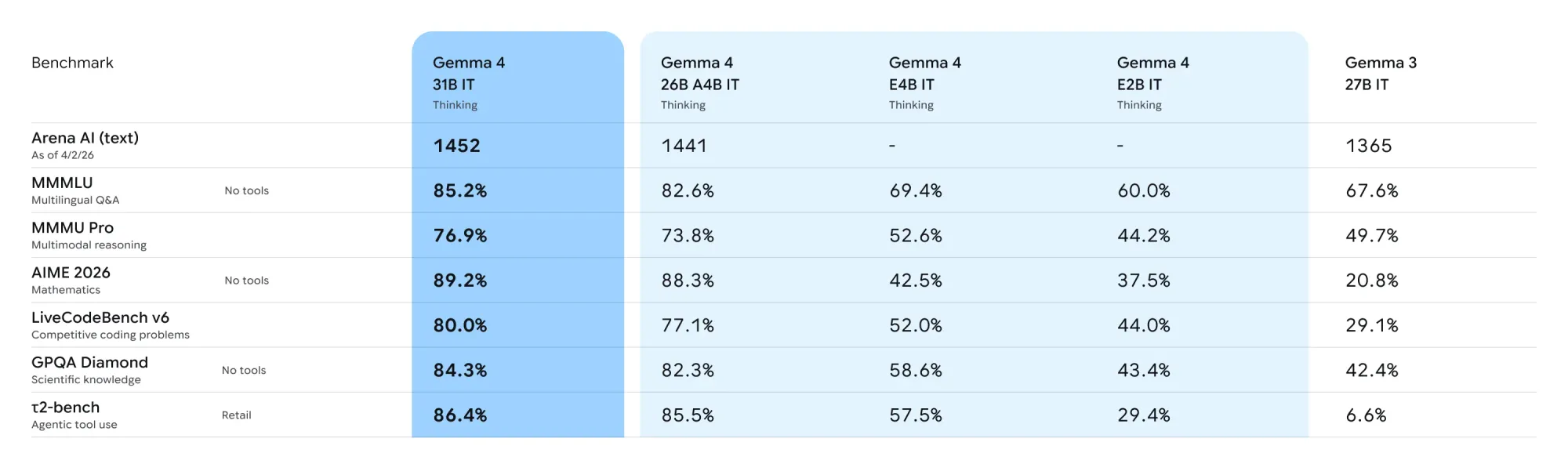
Gemma 4 系列基準測試成績表
註:表格內嘅成績為經過指令微調(Instruction-tuned)模型嘅表現。
| 測試項目 | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B (no think) |
|---|---|---|---|---|---|
| 文字與邏輯推理 (Text) | |||||
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| AIME 2026 no tools | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| Tau2 (average over 3) | 76.9% | 68.2% | 42.2% | 24.5% | 16.2% |
| HLE no tools | 19.5% | 8.7% | - | - | - |
| HLE with search | 26.5% | 17.2% | - | - | - |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 21.9% | 19.3% |
| MMMLU | 88.4% | 86.3% | 76.6% | 67.4% | 70.7% |
| 視覺能力 (Vision) | |||||
| MMMU Pro | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% |
| OmniDocBench 1.5 (越低越好) | 0.131 | 0.149 | 0.181 | 0.290 | 0.365 |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% | 46.0% |
| MedXPertQA MM | 61.3% | 58.1% | 28.7% | 23.5% | - |
| 音訊處理 (Audio) | |||||
| CoVoST | - | - | 35.54 | 33.47 | - |
| FLEURS (越低越好) | - | - | 0.08 | 0.09 | - |
| 長文本處理 (Long Context) | |||||
| MRCR v2 8 needle 128k (avg) | 66.4% | 44.1% | 25.4% | 19.1% | 13.5% |
數據深度分析:跑分背後代表咩實際應用價值?
睇完一堆密密麻麻嘅數字,到底對一般企業同開發者有咩啟示?我哋可以從以下幾個核心範疇去解讀:
1. 編程與數學邏輯:出現飛躍性成長
喺測試編程能力嘅 Codeforces ELO 指標中,上一代 Gemma 3 27B 只有 110 分,但 Gemma 4 31B 竟然飆升至 2150 分,連輕量級嘅 E4B 都有 940 分。呢個極度誇張嘅增長,意味住 Gemma 4 已經由一個「識得傾偈嘅 AI」,進化成一個「專業嘅 AI 程式員」。
對於香港嘅 IT 企業嚟講,可以將 31B 或 26B 模型部署喺本地伺服器,作為開發團隊嘅 Code Review(代碼審查)或自動化編程助手。因為模型具備強大嘅邏輯分析能力(AIME 2026 數學測試達 89.2%),喺處理複雜嘅演算法或建立 AI Agent 自動化工作流時,出錯率會大幅降低。
2. 多模態視覺處理:更精準嘅文件與圖表理解
喺視覺測試方面,OmniDocBench 1.5 係用嚟評估模型處理複雜排版文件(例如收據、報表、PDF)嘅能力(分數越低代表誤差越小)。Gemma 4 31B 取得咗 0.131 嘅優異成績,遠勝上代嘅 0.365。
呢項能力對商業應用非常有價值。香港企業經常需要處理大量中英夾雜嘅合約、發票同財務報表。利用 Gemma 4,企業可以開發出更精準嘅本地 OCR(光學字元辨識)系統,讓 AI 自動閱讀圖表並提取關鍵數據,大大減輕人手輸入嘅負擔。
3. 原生音訊支援:為智能邊緣裝置鋪路
值得留意嘅係,高階嘅 31B 同 26B 模型並無包含音訊處理能力,反而係主打輕量化嘅 E4B 同 E2B 先至有 CoVoST 同 FLEURS 嘅音訊基準測試成績。
呢個佈局好明顯係 Google 有意將語音辨識功能下放至邊緣裝置。對於開發者嚟講,未來可以喺唔依賴雲端連線嘅情況下,直接喺智能手機或智能家居產品上,利用 E2B 模型實現極低延遲嘅語音指令控制,同時完美保障用戶私隱。
4. 長上下文檢索:大海撈針能力提升
MRCR v2 8 needle 128k 測試係模擬喺 12 萬 8 千個 Tokens 嘅超長文本中尋找特定資訊(俗稱大海撈針)。Gemma 4 31B 攞到 66.4% 嘅準確率,比上一代嘅 13.5% 有顯著提升。雖然仍有進步空間,但配合其 256K 嘅最大上下文窗口,已經足夠應付日常處理過百頁法律文件或長篇技術手冊嘅總結與資訊提取工作。
總結:開源 AI 模型嘅新里程碑
綜合各項規格同基準測試數據,Google 今次推出嘅 Gemma 4 系列絕對係誠意之作。佢唔單止喺參數架構上作出咗精細嘅分類(由 2B 到 31B),更重要嘅係喺編程、邏輯推理以及多模態處理上,交出咗令人眼前一亮嘅成績表。
特別係採用 Apache 2.0 授權,令企業同開發者可以安心將呢啲高效能模型應用於商業環境中。無論係想喺手機 App 內置離線 AI 功能(採用 E2B/E4B),定係想喺公司內部建立強大嘅本地 AI 代理(採用 26B MoE/31B),Gemma 4 都提供咗一個極具競爭力、而且免除版權煩惱嘅優質選項。隨住各大開源平台逐步支援,相信好快就會見到更多基於 Gemma 4 開發嘅實用工具同應用程式面世。
Comments ()