實用教學|免費呼叫 150+ 頂級 AI 模型!NVIDIA NIM 平台實用設定指南
近期 AI 領域備受關注嘅 NVIDIA NIM 平台正式開放免費雲端 API,提供超過 150 個熱門 AI 模型(包括 DeepSeek、Llama 等)。本文將為大家詳細拆解 NIM 嘅運作原理、免費 API 申請步驟、焦點模型推介,以及點樣喺本地部署同整合至 AI 代理工具,協助讀者零成本建立高效嘅專屬 AI 工作區。

NVIDIA NIM 係咩?
隨住人工智能技術迅速發展,市場上出現咗大量優秀嘅語言模型。但係對於一般使用者或開發者嚟講,要自行準備強大嘅硬件去運行呢啲模型,成本相當高昂。為咗解決呢個痛點,NVIDIA 推出咗 NVIDIA Inference Microservices (NIM) 平台,並開放免費雲端 API 畀大眾使用。
簡單嚟講,NVIDIA NIM 係一個由 NVIDIA 提供嘅微服務平台。官方將各大熱門嘅 AI 大模型(例如 Llama、DeepSeek 等)預先打包,並部署喺 NVIDIA 具備強大運算能力嘅 GPU 伺服器上。使用者只需要透過簡單嘅 API 呼叫,就可以讓遠端伺服器為你執行運算,無論係生成文章、編寫程式碼定係回答複雜問題,所有繁重嘅工作都由 NVIDIA 嘅伺服器代勞。使用者嘅電腦只需要連接網絡,就可以流暢使用超過 150 個頂級 AI 模型。
除咗雲端服務,NIM 亦提供本地部署選項。如果使用者本身擁有符合規格嘅 NVIDIA 顯示卡,可以將整個微服務下載至個人電腦,以完全離線嘅方式運行,確保資料高度隱私。
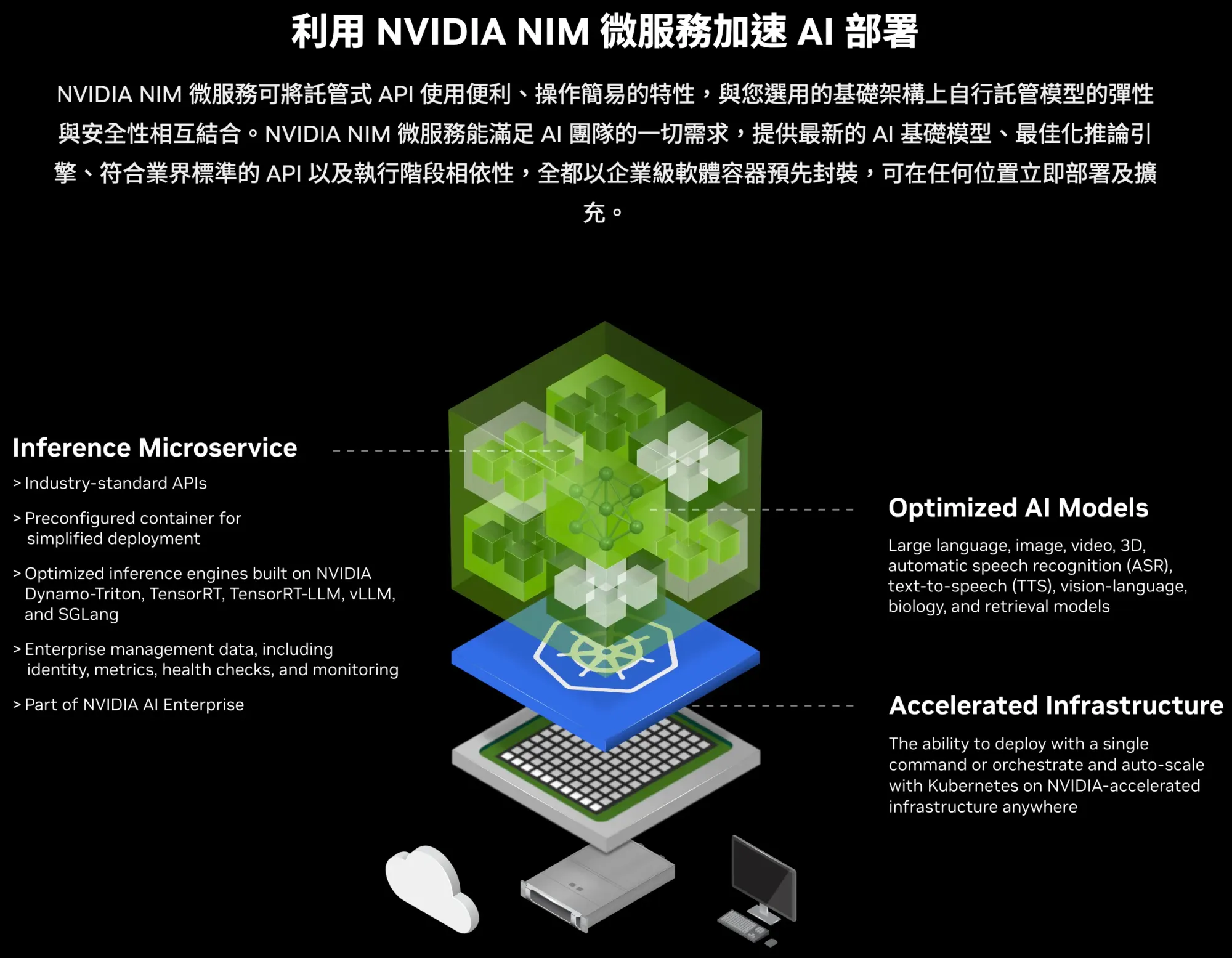
NVIDIA NIM 基本資料整理
要快速了解 NVIDIA NIM 嘅服務架構,可以參考以下表格整理嘅核心資訊:
| 項目 | 說明與規格 |
|---|---|
| 官方網站 | build.nvidia.com |
| 服務類型 | 雲端 AI API 託管 + 可下載本地微服務 (Docker 容器) |
| 模型數量 | 超過 150 個(涵蓋文字、多模態、語音、嵌入向量,並持續更新) |
| 收費模式 | 開發者方案免費;企業級正式部署需購買 NVIDIA AI Enterprise 授權 |
| 免費版限制 | 具備速率限制(Rate Limit):每分鐘最高 40 次請求(40 RPM) |
| API 相容性 | 與 OpenAI API 格式完全相容(只需替換 base_url 及 API Key) |
| 申請門檻 | 毋須綁定信用卡,僅需電郵及手機號碼完成驗證 |
免費雲端 API 申請:詳細使用教學
NVIDIA NIM 最具吸引力嘅地方在於其永久免費嘅開發者方案。即使個人電腦效能一般,甚至只係一部舊款手提電腦,只要完成註冊,就可以取得免費嘅 API 存取權限。整個申請流程相當簡便,以下係逐步拆解嘅操作指南:
步驟一:前往 NVIDIA 平台並登入帳號
首先,打開瀏覽器前往 NIM 嘅 API 目錄平台網站(build.nvidia.com)。喺頁面右上角點擊「Login」。系統會要求輸入電郵地址,如果尚未擁有帳號,可以點擊「更多登入選項」進行全新註冊。
步驟二:完成驗證並建立開發者帳號
喺註冊過程入面,系統會提供多種驗證方式。使用者可以依照畫面指示輸入所需資訊,並接收電郵或手機短訊驗證碼(支援香港及台灣等地區嘅手機號碼)。驗證完成後,系統會要求建立一個 NVIDIA 雲端帳號名稱。點擊確認按鈕即可完成整個註冊程序,過程中絕對唔需要輸入任何信用卡或付款資訊。
步驟三:生成並儲存 API 金鑰 (API Key)
登入平台後,點擊網頁右上角嘅使用者圖示,於下拉式選單中選擇「API Keys」。進入頁面後,你可以為呢個金鑰設定一個易於識別嘅名稱(例如「My_AI_Agent」或「Test_Key_1」),並喺下方選項自訂金鑰嘅有效期限(由一小時至最高一年不等)。確認後點擊「Generate Key」。
系統會隨即生成一串以 nvapi- 開頭嘅字串,呢個就係你嘅專屬 API 金鑰。請務必立即複製並妥善儲存喺安全嘅地方,因為基於安全理由,該金鑰只會喺畫面上顯示一次。
步驟四:於網頁端進行測試及獲取程式碼
取得 API Key 後,你可以直接喺平台上測試各款模型。點擊網頁上方嘅「Models」,左邊會有不同類別嘅篩選器,你亦可以選擇以「Most Popular」(最熱門)進行排序。
選擇心水模型(例如 nemotron-3-super-120b)後,網頁下方會提供一個測試對話框。你可以直接輸入指令(Prompt)測試模型嘅反應速度同質素。
如果想將該模型整合至自己嘅應用程式,點擊右上角嘅「View Code」按鈕。系統會展示適用於 Python、LangChain 等框架嘅標準程式碼。同時,你亦可以喺程式碼入面搵到該模型嘅專屬「Model ID」(例如 nvidia/nemotron-3-super-120b-a12b),呢個 ID 喺後續串接第三方工具時會經常用到。
焦點 AI 模型推介與應用場景
NIM 平台提供超過 150 個模型,涵蓋唔同領域嘅需求。為咗協助大家快速上手,我哋整理咗目前最具實用價值嘅幾款核心模型:
1. 大型語言模型 (LLM) - 文字生成與邏輯推理
- Meta Llama 4 系列:作為開源模型嘅指標,Llama 4 提供卓越嘅邏輯推理能力。NIM 平台上具備提供 128k 特長上下文視窗(Context Window)嘅版本,意味住佢可以一次過處理大量文字數據。非常適合用嚟分析長篇報告、合約文件或進行深度文章摘要。
- DeepSeek V4 / V3.2:呢個系列喺編寫程式碼及數學邏輯推理方面表現極佳。V4 版本更支援高達 1M Token 嘅上下文視窗。如果讀者需要一個 AI 助手協助 Debug 或生成複雜嘅程式腳本,DeepSeek 係一個相當可靠嘅選擇。
- Qwen 2.5 72B (通義千問):對於香港讀者嚟講,處理繁體中文嘅流暢度非常重要。Qwen 2.5 喺中文語意理解同生成質素上處於領先地位,無論係撰寫商業電郵、構思社交媒體文案,定係進行中英雙向翻譯,表現都非常穩定。
- Kimi K2.5:主打 200k 超長上下文處理能力,專門針對需要一次過「消化」數百頁 PDF 文件或整本書籍嘅應用場景。
2. NVIDIA 自家優化模型 (Nemotron 系列)
NVIDIA 運用自身硬件優勢,對一系列模型進行深度優化,統稱為 Nemotron 系列。
- Nemotron 3 Super 120B:屬於旗艦級模型,運算能力強大,特別適合處理需要嚴格遵循結構化指令(如 JSON 格式輸出)或複雜嘅代理人工具呼叫(Tool Calling)任務。
- Nemotron Nano 9B V2:主打輕量及快速回應,適合用於一般日常對話及基礎問答,系統資源消耗極低。
3. 特殊用途模型
- Riva (語音辨識與生成):NVIDIA 自家研發嘅語音模型,能夠提供高精準度嘅語音轉文字(STT)服務,適合用於製作會議紀錄或自動生成影片字幕。
- NV-Embed (向量嵌入模型):專門為構建 RAG(檢索增強生成)知識庫而設,可以將使用者嘅私人文件轉換成向量數據,令 AI 能夠根據專屬資料庫回答問題,確保資訊準確性。
進階教學:本地部署與 Hermes Agent Desktop 整合
雖然雲端 API 已經非常方便,但對於追求極致隱私或具備高階硬件嘅讀者,本地部署同整合 AI 代理人工具係更進階嘅玩法。
方案 A:透過 Docker 進行本地部署
如果電腦配置咗高階 NVIDIA 顯示卡(視乎模型大小,通常需要具備較大 VRAM,如 RTX 4090 或企業級 GPU),你可以將模型完全下載至本地運行:
- 前往 NVIDIA Developer 網站註冊並取得 NGC API Key。
- 確保電腦已正確安裝 Docker Desktop 及 NVIDIA Container Toolkit。
- 透過終端機(Terminal)輸入官方提供嘅 Docker 指令,設定快取路徑並啟動容器。
- 啟動後,本機就會建立一個
http://localhost:8000/v1嘅 API 端點,資料處理完全留喺本機,毋須連接外部網絡。
方案 B:結合 Hermes Agent Desktop 建立專屬 AI 助理
對於一般讀者,更具效益嘅做法係將免費嘅 NIM 雲端 API 整合至第三方 AI 代理工具,例如開源嘅 Hermes Agent Desktop。呢個組合可以令 AI 唔單止識得傾偈,仲能夠自動執行桌面任務。
設定步驟:
- 打開 Hermes Agent Desktop,進入左側選單嘅「Settings」(設定)中嘅「Model」分頁。
- 點擊右上角嘅「+ Add Model」。
- 喺 Provider 下拉式選單入面,選擇「Local/Custom」(因為 NIM 採用相容 OpenAI 嘅自訂端點)。
- Base URL(端點網址):輸入
[https://integrate.api.nvidia.com/v1](https://integrate.api.nvidia.com/v1) - API Key:貼上早前喺 NIM 平台申請,以
nvapi-開頭嘅金鑰。 - Model ID:輸入你想使用嘅模型完整 ID,例如
qwen/qwen2.5-72b-instruct或deepseek-ai/deepseek-v3。 - 儲存設定後,隨意喺對話框輸入測試語句。若果能順利獲得回覆,即代表 AI 代理人已經成功連接 NIM 嘅強大雲端大腦。使用者更可以針對唔同任務(如寫程式、繁體中文寫作)建立多個 Profile,隨時無縫切換合適嘅模型。
雲端 API 與本地部署比較
為咗協助讀者選擇最適合自己嘅方案,以下整理咗雲端與本地部署嘅具體差異:
| 比較項目 | 雲端 API 方案 (build.nvidia.com) | 本地部署方案 (NIM Docker 容器) |
|---|---|---|
| 硬件需求 | 極低(僅需基本網絡連接及瀏覽器) | 極高(需配備大容量 VRAM 嘅 NVIDIA GPU) |
| 部署成本 | 零成本(開發者方案免費) | 需承擔購置高階顯示卡及電力成本 |
| 資料隱私 | 資料需傳輸至 NVIDIA 雲端伺服器進行處理 | 資料完全留存於本地,適合處理機密商業數據 |
| 連線限制 | 受速率限制(每分鐘最高 40 次請求) | 無限制,取決於本地硬件嘅運算速度 |
| 技術門檻 | 低(只需申請金鑰及複製端點網址) | 高(需要熟悉 Docker 及命令列操作) |
| 適用對象 | 學生、一般開發者、AI 工具愛好者 | 具備專業技術背景或對資料安全有嚴格要求之企業用戶 |
功能與使用上嘅注意事項
喺實際應用 NVIDIA NIM 嘅時候,有幾個重點需要特別留意,確保使用體驗流暢:
- 免費方案嘅速率限制 (Rate Limit):目前平台提供嘅免費額度主要以使用頻率計算,限制為每分鐘 40 次請求(40 RPM)。對於個人編寫程式、日常查詢或一般 AI 代理人任務而言,呢個額度已經非常充足。但若果需要進行大量自動化批次處理(Batch Processing),則可能會觸發限制而導致連線暫停。
- 商用授權問題:免費方案明確定義為提供予開發與測試用途。若果讀者打算將 AI 模型整合至對外收費、具備大流量嘅正式商業產品之中,必須向官方購買 NVIDIA AI Enterprise 授權,以符合合法合規嘅商業使用條款。
- 資料處理與傳輸:使用雲端 API 意味住你嘅 Prompt(提示詞)同上傳嘅文件會傳送至 NVIDIA 嘅伺服器進行推論。儘管官方具備完善嘅私隱保護機制,但若果涉及高度敏感嘅個人或企業機密資料,建議依然採用本地部署方案最為穩妥。
- 模型相容性:雖然 NIM 提供嘅端點與 OpenAI 完全相容,但部分依賴 OpenAI 特定功能(如 Assistant API 內部嘅專有架構)嘅複雜應用程式,未必能夠 100% 無縫切換。喺大規模套用前,建議先進行小規模測試。
總結
綜合各項功能與實際操作體驗,NVIDIA NIM 平台確實為 AI 開發者及一般使用者提供咗極具價值嘅資源。透過免費開放超過 150 個高效能模型嘅 API 存取權限,NIM 大幅降低咗應用頂級 AI 技術嘅門檻。使用者毋須花費巨額資金購置硬件,亦毋須處理繁瑣嘅環境設定,即可透過雲端算力完成多樣化嘅任務。
無論讀者嘅目標係想簡單測試各款模型嘅效能差異,抑或打算為個人工作區建立一個由 DeepSeek 或 Llama 驅動嘅自動化 AI 代理人,NVIDIA NIM 嘅解決方案都提供咗極大嘅彈性與實用性。建議有興趣提升數碼工作效率嘅讀者,可以根據本文嘅步驟先行註冊並取得 API 金鑰,親身體驗呢項技術帶嚟嘅便利。
常見問題 Q&A
1. NVIDIA NIM 究竟係咩?
NIM 全稱為 NVIDIA Inference Microservices,係 NVIDIA 提供嘅 AI 模型推論服務。佢將各大熱門 AI 模型部署於雲端伺服器,讓使用者透過 API 呼叫,直接利用 NVIDIA 嘅算力執行任務。
2. 申請及使用 NIM 雲端 API 需要收費嗎?
開發者方案係完全免費嘅。註冊過程毋須綁定信用卡,使用者只需遵守官方設定嘅連線速率限制即可免費使用。
3. 免費方案嘅具體限制係咩?
主要限制為請求速率(Rate Limit),目前設定為每分鐘最多 40 次請求(40 RPM)。呢個頻率對於一般個人使用、測試及 AI 代理人操作已經相當夠用。
4. 平台支援邊種 API 格式?
NIM 嘅 API 格式與 OpenAI 完全相容。使用者只需將現有程式碼入面嘅伺服器網址(base_url)替換為 NIM 嘅端點,並更改 API 金鑰與模型名稱即可運作。
5. 平台上有邊啲熱門嘅 AI 模型可以使用?
平台提供超過 150 個模型,包括備受歡迎嘅 Meta Llama 4、DeepSeek V4、月之暗面 Kimi K2.5、阿里 Qwen 2.5,以及 NVIDIA 針對性優化嘅 Nemotron 系列。
6. 如果主要處理繁體中文內容,應該選擇邊個模型?
處理繁體中文時,建議優先選擇 Qwen 2.5 (72B) 或 GLM-5.1。呢幾款模型喺中文語境理解及生成流暢度方面具備顯著優勢。
7. 點樣可以搵到用作程式碼串接嘅 Model ID?
登入 NIM 平台後,點選心水模型並進入測試頁面。點擊右上角嘅「View Code」按鈕,喺顯示嘅程式碼範例入面,model= 後方引號內嘅字串就係完整嘅 Model ID。
8. 本地部署 NIM 容器有咩硬件要求?
本地部署需要依賴 NVIDIA 顯示卡。硬件需求取決於模型大小,一般 8B 參數嘅模型最少需要 8GB VRAM(如 RTX 系列);大型模型則可能需要企業級 GPU(如 A100 或 H100)才能順暢運行。
9. 將 NIM API 串接至 Hermes Agent Desktop 有咩好處?
呢個組合可以零成本建立個人專屬 AI 助理。Hermes 負責提供桌面自動化與管理功能,而 NIM 則提供強大嘅雲端語言模型大腦,兩者結合可以免除本地算力不足嘅問題。
10. 免費版 API 可以用於公司嘅正式商業產品嗎?
官方政策指出,免費開發者方案僅供測試及開發用途。若需於具備大流量嘅正式商業產品中部署,企業必須購買 NVIDIA AI Enterprise 付費授權。



