Ollama 0.19更新 全面支援 MLX 框架,Mac 運行 AI 效能大幅提升
知名本機 AI 運行工具 Ollama 推出 0.19 預覽版,正式整合 Apple 嘅 MLX 機器學習框架。更新後,配備 Apple Silicon 嘅 Mac 電腦喺處理提示詞同生成回應嘅速度有顯著提升,當中以 M5 系列晶片受惠最大。不過,用家需要留意,目前系統要求 Mac 具備至少 32GB 統一記憶體,而且暫時只支援 Qwen3.5 模型。呢次更新為需要高私隱度同本地運算嘅開發者提供咗更強大嘅基礎。

Ollama 迎接架構大升級
喺人工智能技術快速發展嘅今日,越嚟越多用家希望可以喺自己嘅電腦上運行 AI 模型,以保障資料私隱同埋節省訂閱雲端服務嘅費用。一直備受開發者同科技愛好者歡迎嘅本機 AI 運行應用程式 Ollama,近日釋出咗 0.19 預覽版。呢次更新最核心嘅改變,係正式建立喺 Apple 專為自家晶片設計嘅機器學習框架——MLX 之上。透過充分利用 Apple Silicon 嘅統一記憶體架構(Unified Memory Architecture),Ollama 成功為 Mac 用家帶來大幅度嘅效能提升。呢篇報道會為大家詳細拆解今次更新嘅重點、背後嘅技術原理,以及對一般用家嘅實際影響。
Ollama 同本機 AI 點解越嚟越重要?
喺了解今次效能提升之前,我哋首先要明白點解本機 AI(Local AI)會受到市場重視。目前大眾最熟悉嘅 AI 服務,例如 ChatGPT 或者 Claude,絕大多數都係基於雲端運作。當用家輸入問題時,資料會傳送到供應商嘅伺服器進行處理,然後再將結果傳回。
雖然雲端 AI 能夠提供最強大嘅運算能力,但同時衍生出幾個問題。首先係私隱風險,對於需要處理商業機密、病人資料或者敏感源代碼嘅專業人士嚟講,將資料上傳到第三方伺服器係不可接受嘅。其次係網絡依賴,雲端服務必須喺有網絡連線嘅情況下先可以運作。最後係成本問題,長期依賴高階雲端 API 會產生龐大嘅費用。
Ollama 嘅出現正正係為咗解決呢啲痛點。佢係一款支援 Mac、Linux 同 Windows 嘅開源應用程式,容許用家將大型語言模型(LLM)下載到本地電腦,直接利用本機嘅 CPU 同 GPU 進行運算。用家可以從 Hugging Face 等開源社群,甚至模型開發商直接下載模型。所有資料都留喺本地電腦,無需互聯網連線都可以正常運作,提供咗極高嘅安全性同自主性。
Apple MLX 框架係咩?效能提升有幾明顯?
要喺本地電腦流暢運行 LLM 其實充滿挑戰,因為即使係輕量級嘅語言模型,運作時都需要消耗大量嘅隨機存取記憶體(RAM)同埋顯示卡記憶體(VRAM)。傳統電腦架構中,CPU 同 GPU 嘅記憶體係分開嘅,數據喺兩者之間傳輸會造成樽頸。
Apple Silicon(由 M1 到最新嘅 M5 系列晶片)採用咗「統一記憶體架構」,即係 CPU 同 GPU 共享同一個高頻寬記憶體池。為咗完全發揮呢個硬件優勢,Apple 推出咗開源機器學習框架 MLX。Ollama 0.19 預覽版轉用 MLX 框架後,可以更直接、更高效地調度 Mac 嘅硬件資源。
根據 Ollama 官方公佈嘅數據,新版本喺效能上有以下顯著改善:
- 提示詞處理速度(Prefill Speed): 處理用家輸入嘅提示詞速度提升咗約 1.6 倍。即係話,當你輸入一段長篇幅嘅文章要求 AI 總結時,系統理解文章嘅時間會大幅縮短。
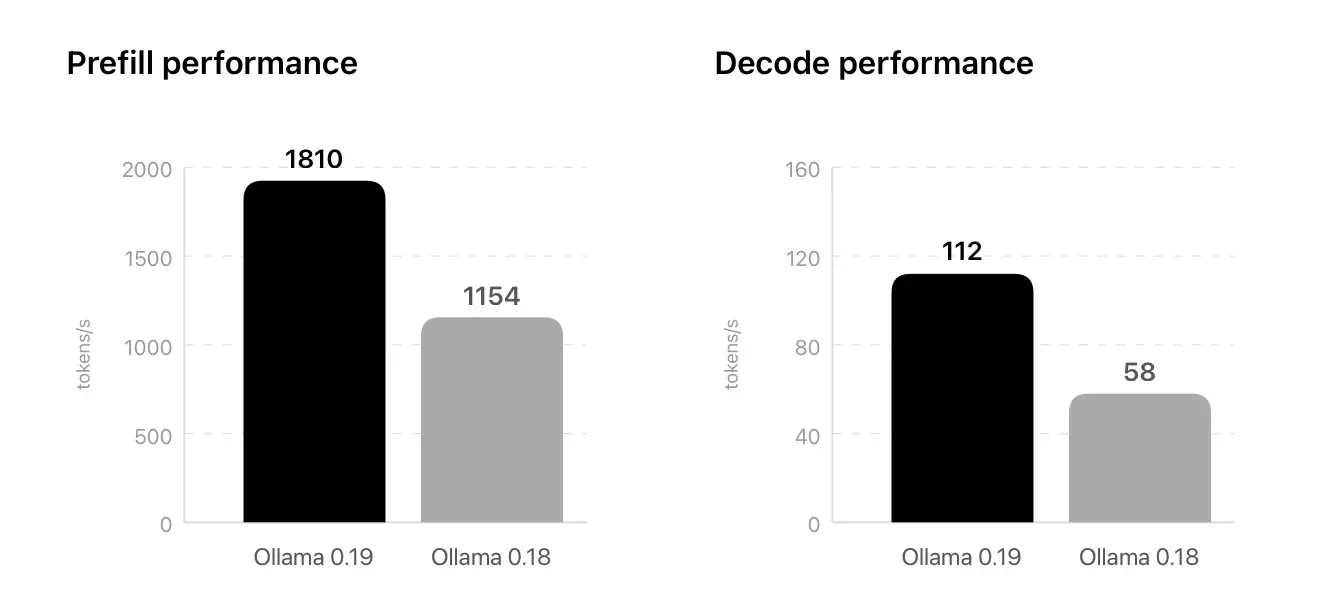
- 生成速度(Decode Speed): 生成文字回應嘅速度幾乎提升咗一倍。用家可以明顯感覺到 AI 輸出文字嘅流暢度更高,減少等待時間。
- 首次信號傳輸時間(Time to First Token, TTFT): 系統給出第一個字嘅反應時間變得更短,令整體互動體驗更接近即時對話。
M5 晶片系列成為最大贏家
雖然所有配備 Apple Silicon 嘅 Mac 都可以從 MLX 框架中受惠,但 Ollama 特別指出,配備最新 M5 系列晶片(包括 M5、M5 Pro 同 M5 Max)嘅電腦,將會獲得最巨大嘅效能提升。原因在於 Ollama 能夠調用 M5 晶片內置嘅全新「GPU 神經網絡加速器」(GPU Neural Accelerators),進一步推高運算極限。呢項技術結合更聰明嘅記憶體管理機制,令到 AI 喺長時間運作時,依然可以保持極高嘅穩定性同反應速度。
實際應用場景:對香港用家有咩幫助?
技術規格嘅提升,最終都係為咗服務實際嘅應用場景。對於香港嘅用家嚟講,Ollama 嘅效能躍升喺以下幾個範疇特別有用:
- AI 編程助手(Coding Agents): 越嚟越多軟件工程師依賴 AI 協助編寫代碼、尋找程式錯誤(Debug)同埋撰寫技術文件。Ollama 特別提到,運行 Claude Code、OpenCode 或者 Codex 呢類專為編程設計嘅 AI 代理時,新版本會令反應變得更加敏捷。開發者可以喺本地環境中即時測試代碼,唔需要擔心公司嘅機密代碼外洩,同時享受媲美雲端服務嘅流暢度。
- 個人助理工具: 唔少專業人士會使用好似 OpenClaw 呢類本地個人助理,協助處理日常文書工作、整理會議記錄或者進行數據初步分析。由於新版本改善咗記憶體管理,即使助理程式喺背景長時間運行,都唔會嚴重拖慢整部 Mac 嘅運作速度。
- 本地知識庫搜尋: 企業或者學術研究人員可以將大量內部文件轉換成向量數據,配合 Ollama 喺本地進行檢索增強生成(RAG)。效能提升意味著系統可以喺更短時間內閱讀並綜合幾百份文件,給出精準嘅答案。
升級與使用限制:硬件要求與目前支援狀況
雖然更新帶來嘅好處十分吸引,但讀者喺決定安裝之前,必須清楚了解 Ollama 0.19 預覽版嘅硬件門檻同埋現有嘅限制。
首先,Ollama 官方指出,用家嘅 Mac 必須配備「超過 32GB 嘅統一記憶體」先好嘗試運行呢個版本。呢個要求對於一般消費者嚟講相對嚴苛。點解需要咁多記憶體?因為大型語言模型嘅參數檔案非常龐大,而且運作期間需要佔用大量記憶體空間去儲存上下文資訊。如果記憶體不足,系統需要頻繁將數據寫入硬碟(Swap),將會導致速度大幅下降,完全抵銷咗 MLX 框架帶來嘅優勢。因此,如果讀者目前使用 8GB 或 16GB 記憶體嘅 MacBook,可能需要等待未來進一步嘅優化版本。
其次,喺支援嘅模型方面,目前 Ollama 0.19 預覽版暫時只支援由阿里巴巴開源嘅 Qwen3.5 模型。Qwen3.5 係一個功能強大嘅多語言模型,喺處理中文方面有唔錯嘅表現。不過,如果你習慣使用 Llama 3、Mistral 等其他主流開源模型,就需要耐心等待。Ollama 已經表明,未來會陸續加入對更多 AI 模型嘅支援。
比較分析:雲端 AI 與本機 AI (Ollama) 嘅客觀對比
為咗幫助讀者更客觀咁評估自己係咪適合轉用本機 AI,我哋整理咗一個簡單嘅比較表,從幾個關鍵維度分析雲端 AI 服務同使用 Ollama 運行本機 AI 嘅差異:
| 比較項目 | 雲端 AI 服務 (如 ChatGPT) | 本機 AI (Ollama 配合 Apple MLX) |
|---|---|---|
| 資料私隱度 | 較低(資料需上傳至伺服器處理) | 極高(所有運算喺本地完成,資料不離機) |
| 網絡依賴 | 必須連接互聯網 | 可完全離線運作 |
| 運作成本 | 持續嘅按月訂閱費或按量收費 | 零軟件使用費(但前期硬件投資成本較高) |
| 硬件要求 | 極低(瀏覽器運作流暢即可) | 極高(需強大 CPU/GPU 及高容量統一記憶體,如 32GB 以上) |
| 運算速度 | 視乎網絡狀況及伺服器負荷 | 穩定,取決於本地電腦硬件效能(MLX 框架有顯著提速) |
| 模型選擇 | 供應商提供嘅固定模型 | 高度自由,可隨時切換及下載不同開源模型 |
透過上面嘅比較可以見到,本機 AI 同雲端 AI 各有優劣。對於資源有限、只係間中需要 AI 協助寫作或者翻譯嘅一般用家,雲端服務依然係最方便、最具成本效益嘅選擇。但對於企業開發團隊、對資料安全有極高要求嘅機構,或者本身已經擁有高階 Mac 設備嘅專業人士,Ollama 配合 MLX 框架提供咗一個極具潛力嘅高效方案。
總結與展望
Ollama 0.19 預覽版引入 Apple MLX 框架,標誌住 Mac 平台喺本機 AI 運算領域邁出咗重要一步。高達 1.6 倍嘅提示詞處理速度同翻倍嘅生成速度,加上 M5 晶片神經網絡加速器嘅配合,令本地運行大型語言模型變得更具實用價值。
雖然目前 32GB 統一記憶體嘅硬件門檻,以及暫時只支援 Qwen3.5 模型嘅限制,令呢個預覽版未必適合所有用家,但呢次技術更新清晰咁展示咗未來嘅發展方向。隨著 Apple Silicon 硬件技術不斷推進,以及 Ollama 未來擴展模型支援陣容,本機 AI 嘅應用場景將會越嚟越普及。對於正計劃為高用量工作升級設備嘅專業人士而言,本機 AI 嘅運算效能,將會成為未來評估電腦配置時一個重要嘅參考指標。
Comments ()