Google 最新 Android 測試報告:Gemini 3.5 Flash 編程效能爆冷落後,GPT 5.5 奪冠
Google 最新發布嘅 Android Bench 程式碼測試結果顯示,定位高階嘅 Gemini 3.5 Flash 表現未如預期,不但跌出前五名,更落後於舊版 Gemini 3.1 Pro Preview。相反,OpenAI 嘅 GPT 5.5 穩佔榜首。令人意外嘅係,Gemini 3.5 Flash 嘅運行成本屬全榜最高,反映新一代 AI 模型喺特定開發任務上嘅性價比仍有待改善。

Android Bench 排行榜大洗牌:OpenAI 拋離對手,Google 舊版模型反勝新版
Google 最近更新咗 Android Bench 嘅排行榜數據,呢個排行榜專門用嚟評估市面上各大人工智能(AI)模型喺執行 Android 應用程式開發任務時嘅表現。不過,最新嘅測試結果令唔少科技界人士同埋軟件開發者感到意外。Google 最新推出嘅 Gemini 3.5 Flash 模型,喺評分上明顯落後於上一代產品,而令人震驚嘅係,呢個型號嘅使用成本比起舊版高出三倍。目前,競爭對手 OpenAI 嘅型號依然穩佔排行榜首位,反映出不同廠商喺代碼生成技術上嘅實力差距。
Gemini 3.5 Flash 未能躋身前五
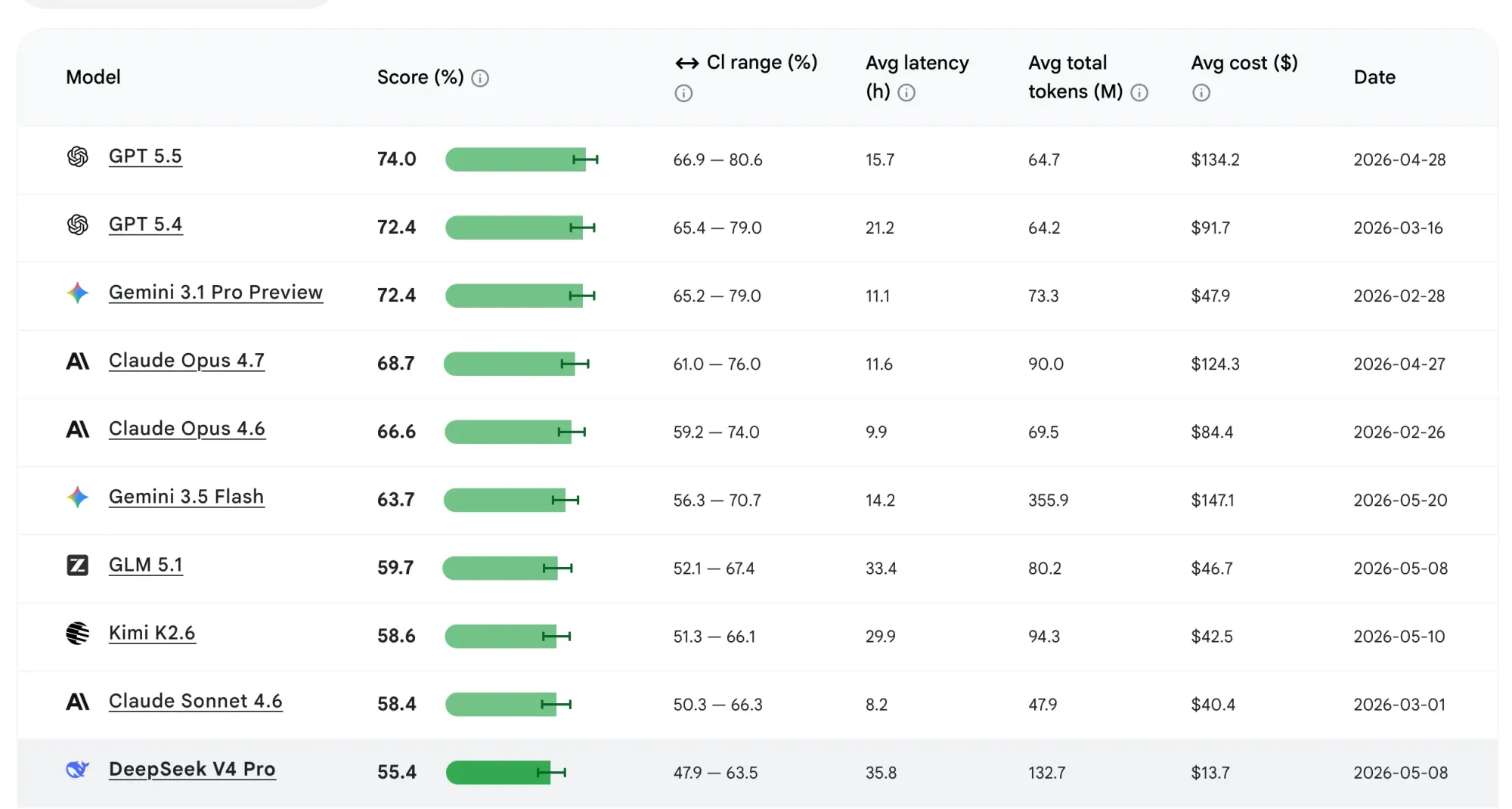
根據 Android 開發排行榜嘅最新數據,Gemini 3.5 Flash 首次被納入評測範圍,但成績並唔理想,甚至未能打入排行榜嘅首五名位置。詳細嘅評分數據反映咗現時 AI 模型喺編程領域嘅版圖分佈。
排喺榜首嘅係 OpenAI 最新嘅 GPT 5.5 模型,以 74 分嘅高分傲視同儕。緊隨其後嘅係 OpenAI 嘅上一代模型 GPT 5.4,以及 Google 較早期推出嘅 Gemini 3.1 Pro Preview,兩者同樣獲得 72.4 分,並列第二。此外,Anthropic 推出嘅新一代 Claude Opus 模型,喺是次測試入面嘅表現亦成功超越咗 Gemini 3.5 Flash。
至於備受矚目嘅 Gemini 3.5 Flash,最終得分只有 63.7 分,排喺整體第六位。呢個得分不但同榜首有明顯距離,亦低過同廠較舊嘅型號,情況令開發者重新評估應否立即升級使用最新嘅開發工具。
成本與效能對比:標榜經濟高效卻成最昂貴選項
喺效能評分之外,Android Bench 亦提供咗關於成本與運作效率嘅數據。根據測試紀錄,Gemini 3.5 Flash 喺執行任務時,平均需要消耗 355.9 個 Token(標記)。同排行榜上面其他系統比較,呢個消耗量出現咗大幅度嘅飆升。
Token 消耗量直接影響開發者需要支付嘅 API(應用程式介面)費用。數據指出,Gemini 3.5 Flash 每次執行任務嘅平均成本高達 147.1 美元。呢個驚人嘅數字,令佢成為整個測試名單入面最昂貴嘅模型選項。對於商業開發團隊嚟講,一個運行速度較慢、效能評分較低,但收費卻係全場最貴嘅工具,顯然欠缺足夠嘅吸引力。外國科技網站嘅分析亦指出,Gemini 3.1 Pro Preview 提供咗顯著更佳嘅編程表現,但成本只係 Gemini 3.5 Flash 嘅大約三分之一。呢種「高價低配」嘅現象,成為咗今次評測入面最大嘅爭議點。
回顧 Google I/O 2026:官方承諾與現實結果嘅落差
要理解點解今次測試結果會引起極大迴響,我哋需要回顧 Google 對呢款模型嘅市場定位。一直以嚟,Google 賦予「Flash」系列嘅品牌形象,主打嘅賣點就係「速度快」同埋「價格親民」,專門針對需要快速反應同埋大規模部署嘅應用場景。
喺 2026 年舉行嘅 Google I/O 開發者大會上面,官方正式發表 Gemini 3.5 Flash,並宣稱呢個係佢哋歷來打造過最強大嘅 Flash 模型。當時 Google 強調,新模型具備更完善嘅程式碼編寫能力,並且能夠更有效支援 AI 代理(AI Agents)以及複雜嘅工作流程。官方更引述內部測試數據指出,Gemini 3.5 Flash 喺多項指標上超越咗 Gemini 3.1 Pro,生成內容嘅速度更加係其他競爭對手旗艦模型嘅四倍。
然而,今次針對 Android 開發而設嘅第三方基準測試,卻反映出截然不同嘅情況。雖然 Gemini 3.5 Flash 可能喺 Google 內部負責評估通用任務同埋代理任務嘅測試入面表現出色,但當面對真實嘅 Android 開發環境同埋具體編程任務時,其表現就顯得相當乏力。呢個落差顯示,AI 模型喺通用測試中嘅高分,未必能夠完全轉化為特定專業領域上嘅實際工作能力。
附加資料整理:了解 AI 編程測試與行業發展
為咗令大家更深入理解今次事件嘅背景,以下整理咗關於 AI 模型編程能力以及相關基準測試嘅幾項關鍵資訊:
1. 甚麼是 Android Bench?
Android Bench 係一個專門設計嚟測試大語言模型(LLM)處理 Android 原生應用程式開發能力嘅基準評估工具。同一般測試寫 Python 或者網頁前端代碼唔同,Android 開發涉及複雜嘅生命週期管理、UI 架構建立(例如 Compose)、背景服務以及與各種硬件感測器嘅互動。模型需要準確理解 Android SDK 嘅邏輯,先能夠生成能夠成功編譯並且無錯誤嘅程式碼。因此,能夠喺呢個測試中取得高分,代表該模型具備極高嘅專業知識水平。
2. 為何 Token 消耗量會影響成本?
喺 AI 開發領域,API 嘅收費模式通常係按照模型處理嘅 Token 數量嚟計算。Token 可以理解為文字嘅基本單位(例如一個英文字母、一個詞根或者一個中文字)。當一個模型喺解決相同問題時,如果需要輸出或者消耗多幾倍嘅 Token,就代表佢嘅運作邏輯可能過於冗長,或者無法一針見血地俾出答案。Gemini 3.5 Flash 喺測試中高達 355.9 嘅平均 Token 消耗量,正正反映佢喺理解同埋編寫 Android 程式碼時可能「行咗遠路」,從而導致成本大幅上漲。
3. 目前 AI 編程模型嘅三大陣營
步入 2026 年下半年,香港、台灣以及新加坡等華人地區嘅科技企業,喺選擇 AI 編程輔助工具時,主要圍繞三大陣營進行評估:
- OpenAI (GPT 系列):今次榜首嘅 GPT 5.5 展現咗強大嘅邏輯推理能力,特別喺處理複雜且需要深層次理解嘅框架開發時,出錯率最低,係目前大型企業開發核心系統嘅首選。
- Google (Gemini 系列):雖然最新嘅 Flash 版本失利,但舊版本如 3.1 Pro Preview 依然表現出眾,而且與 Google 自身生態系統(如 Android Studio)嘅整合度具有先天優勢。
- Anthropic (Claude 系列):Claude Opus 以極長嘅上下文記憶(Context Window)同埋流暢嘅語法結構見稱,對於需要閱讀大量現有專案代碼先可以進行修改嘅任務,表現相當優異。
4. 開發者如何制定部署策略?
根據今次嘅數據分析,業界專家普遍建議開發團隊唔好盲目追求「最新版本」。特別係喺預算有限嘅情況下,選擇性價比最高嘅工具先係最理智嘅做法。例如,處理一般性嘅代碼審查(Code Review)或編寫簡單函數,可以採用成本較低嘅舊版模型;而面對架構設計等高難度任務,先動用成本較高嘅 GPT 5.5,咁樣可以有效平衡開發開支與產品質素。
總結:開發者應按實際需求選擇合適工具,靜候後續更新
今次 Android Bench 嘅測試結果帶出咗一個重要訊息:喺瞬息萬變嘅 AI 領域入面,新型號並不必然等於全面超越舊型號。Gemini 3.5 Flash 喺特定嘅 Android 開發場景下遭遇滑鐵盧,加上高昂嘅運行成本,確實令業界大跌眼鏡。
對於現時面臨選擇困難嘅軟件工程師以及企業 IT 部門嚟講,數據證明舊版嘅 Gemini 3.1 Pro Preview 或者對手嘅 GPT 系列,暫時仍然係處理代碼任務較為可靠同具備經濟效益嘅選擇。目前市場嘅焦點,已經轉移到 Google 將會如何透過軟件更新嚟優化 Gemini 3.5 Flash 嘅代碼生成效率,以及即將推出、定位更高階嘅 Gemini 3.5 Pro 能否真正兌現官方當初定下嘅效能承諾,為 Google 挽回喺專業開發者市場嘅優勢。各界將會繼續密切留意後續嘅評測報告。



